【原创】Vivado HLS中四种数组端口实现方法的对比
0赞在Vivado HLS中,C代码中的数组作为端口时,它们被默认综合为RAM端口。以下面的程序为例:
void array_io (dout_t d_o[N], din_t d_i[N])
{
int i, rem;
// Store accumulated data
static dacc_t acc[CHANNELS];
// Accumulate each channel
For_Loop: for (i=0;i<N;i++) {
rem=i%CHANNELS;
acc[rem] = acc[rem] + d_i[i];
d_o[i] = acc[rem];
}
}
在综合之后,端口被处理为:
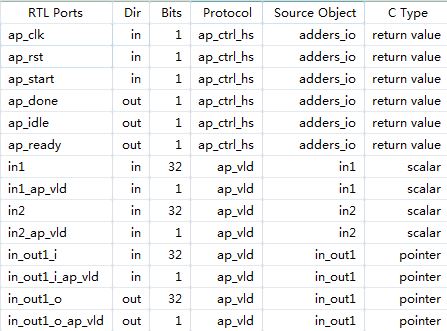
图1 数组端口的默认综合结果
从图1中可以看出,输出数组d_o被ap_memory协议综合为端口,且Vivado HLS自动添加了输出数据端口d_o_d0、使能信号d_o_ce0、写使能端口d_o_we0、输入数据端口d_i_q0。输入数据没有生成写使能端口,因为它只需要读取输入数据。因为这个例子里for循环默认是串行执行的,读操作和写操作没有同时发生,所以数组端口被实现为单口RAM了。根据需要,我们还可以把数组接口综合为双口RAM、FIFO或者把它们展开为多个独立的端口。仍然以图1对应的源代码为例,下面就来看一下它们分别是如何实现的。
1. 数组端口实现为双口RAM和FIFO
上面的例子里,for循环是串行执行的,所以单口RAM就能满足要求了。如果我们想把数组实现为双口RAM,那么for循环就需要被配置成并行循环的,也就是循环展开。在Vivado HLS中打开源程序,然后通过Directive视图改变for循环的配置为展开,如图1所示。
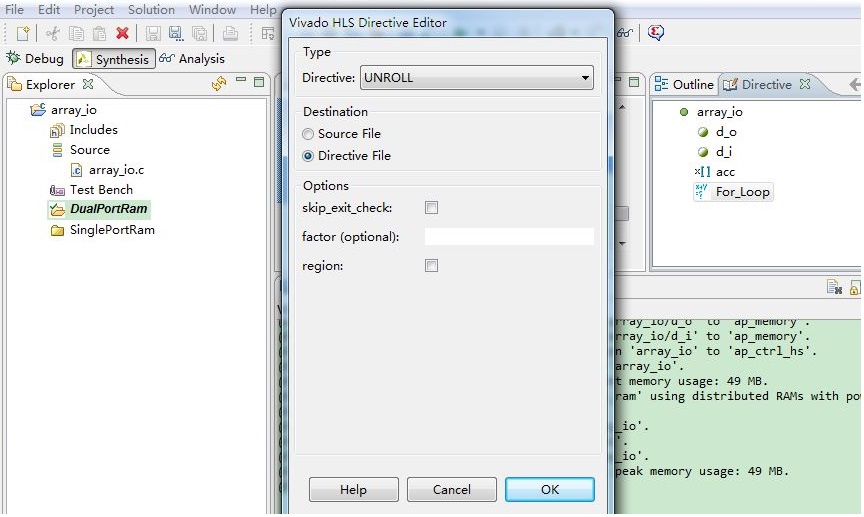
图2 展开for循环
在Directive视图中,我们还可以配置端口使用的资源,例如把输入d_i配置为双口RAM,如图3所示。
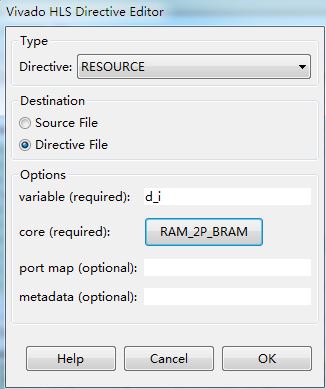
图3 配置端口的资源为双口RAM
按照类似的方法,把输出端口d_o的接口类型INTERFACE配置为ap_fifo类型。最终修改之后的指示文件的视图如图4所示。
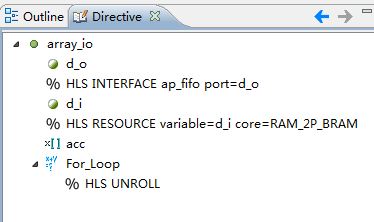
图4 修改结果
然后运行C代码综合,结果如图5所示。
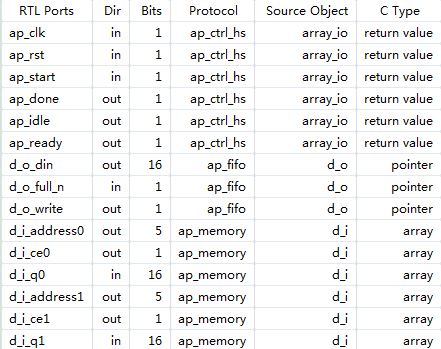
图5 双口RAM的综合结果
从图5中可以看出,输入端口d_i已经具有双口RAM的接口,它有两条地址线,两个独立的输入和两个使能端口。
2. 数组的分割
在接口综合的时候,Vivado HLS可以根据我们预先定义的因子,对数组进行分割,分割方法如图6所示。
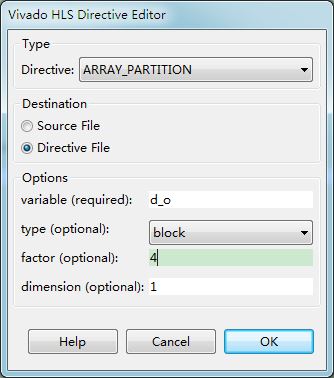
图6 数组分割
在这里,我们把d_i分割为2部分,把d_o分割为4部分,进行C代码综合;然后把d_i和d_o都分割为4部分,再运行C代码综合,对比其端口的综合结果,分别如图7左图、右图所示。
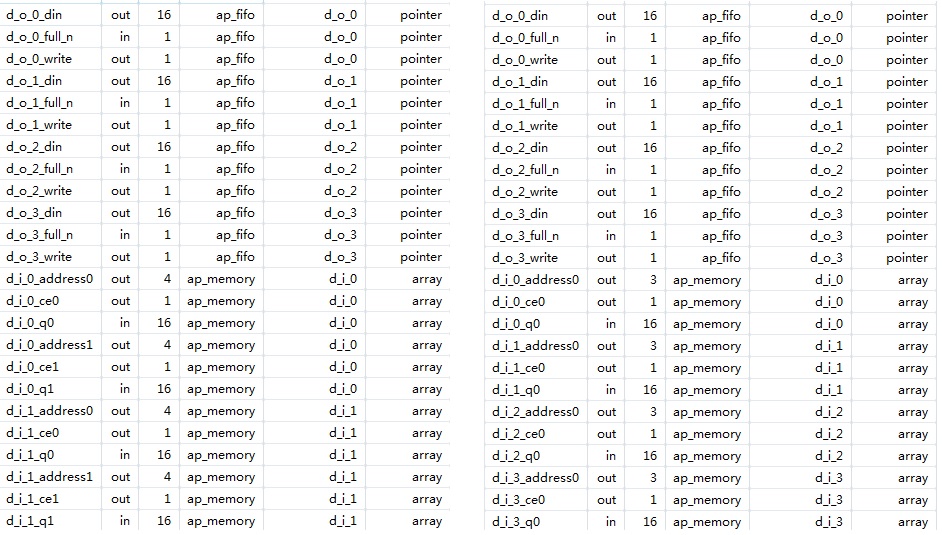
图7 数组分割结果
从图7中可以看出,当d_i分割为2部分,把d_o分割为4部分时,d_i仍然为双口RAM输入,但是当d_i和d_o分割为相同多的份数时,d_i的双口RAM的配置被Vivado HLS自动优化掉了:它被优化为4个单口RAM,与4个输出端口一一对应。
3. 完成展开数组
完全展开数组,意味着把数组里的每个元素都当作单独的端口进行处理,这样可以最大限度地并行运算,提高运行速度,当然占用的器件资源也会相应地增多。展开方法与图6相同,只不过是把展开的类型从block改成complete,如图8所示。
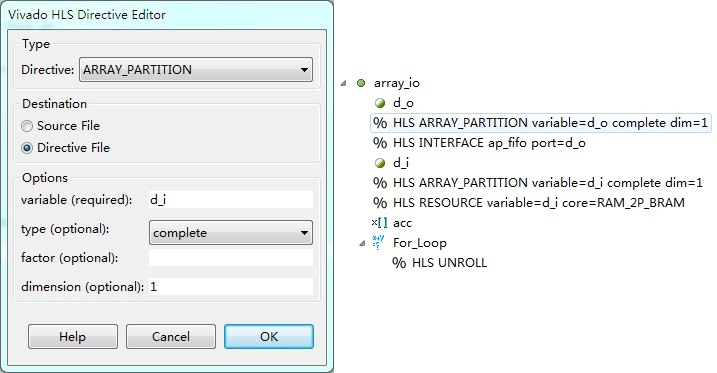
图8 完全展开数组的选项
用图8把d_i和d_o都配置为完全展开之后,端口的综合结果如图9所示。
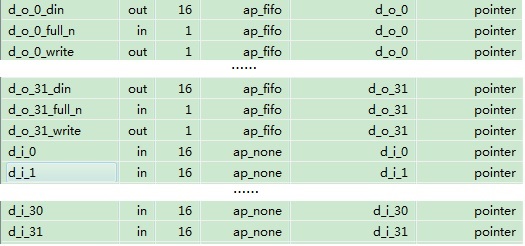
图9 数组完全展开之后的综合结果
因为结果较长,在图9中没有全部列出,可以看出d_o和d_i都被完全展开了。
最后,我们可以对比一下单口RAM、双口RAM、部分展开和全部展开情况下的性能和资源利用率情况,如图10所示(这里使用的开发板是MicroZed)。
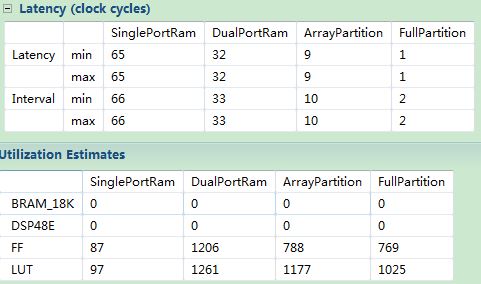
图10 不同综合方法的性能与资源对比

