【原创】在Vivado HLS中如何优化程序的执行速度
0赞
首先新建一个Vivado工程,并输入C代码,然后进行对C代码的高层次综合,综合结果如图1所示。
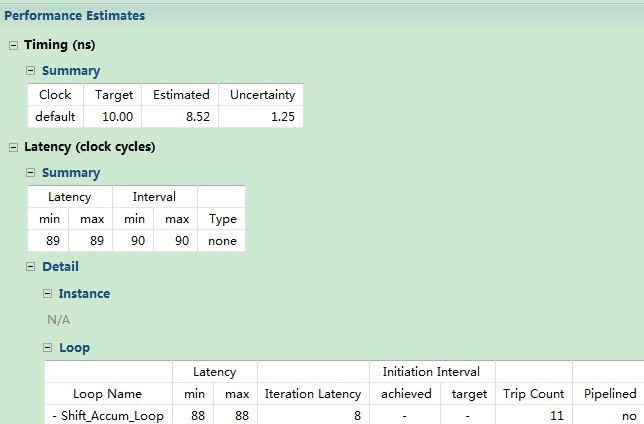
图1 综合后的资源利用率
从图1中可以看出:
1. 目前我们的设计的延时是89个(latency)时钟周期,也就是说需要89个时钟周期后结果才能刷新输出结果。
2. 两次读取输入信号运行之间的间隔是90个(Interval)时钟周期,说明在上一次运算输出写操作完成之后,需要等待一个时钟周期,表明目前我们的设计没有进行流水线优化。
3. 在C程序中,我们使用了循环,这段逻辑被执行了11次(Trip Count),每次需要8个时钟周期(Iteration Latency)。
显然89个时钟周期对一个FIR滤波器来说不算快,所以我们要分析一下程序中的性能瓶颈,然后才好对症下药。点击Vivado HLS菜单栏上的Analysis视图(或者点击Window---Analysis Perspective),打开详细的性能分析和资源利用率报告,分别如图2、图3所示。
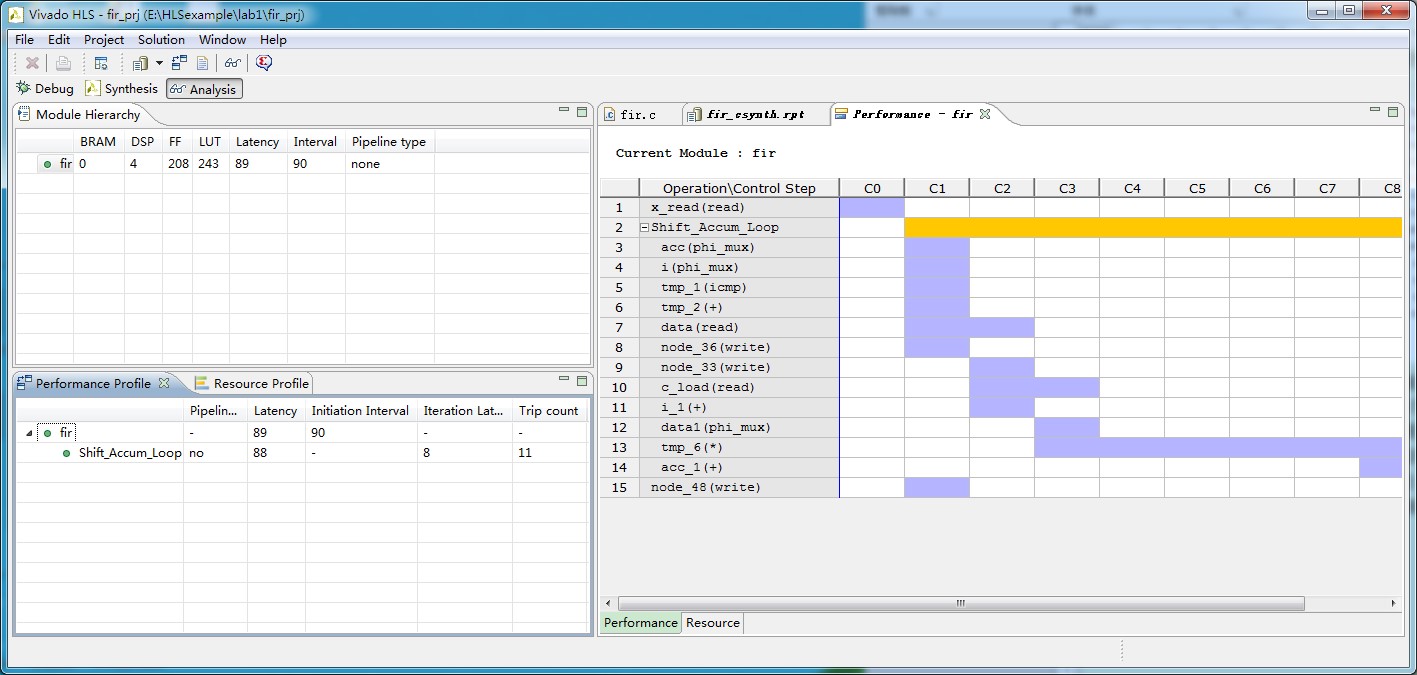
图2 详细的性能分析视图
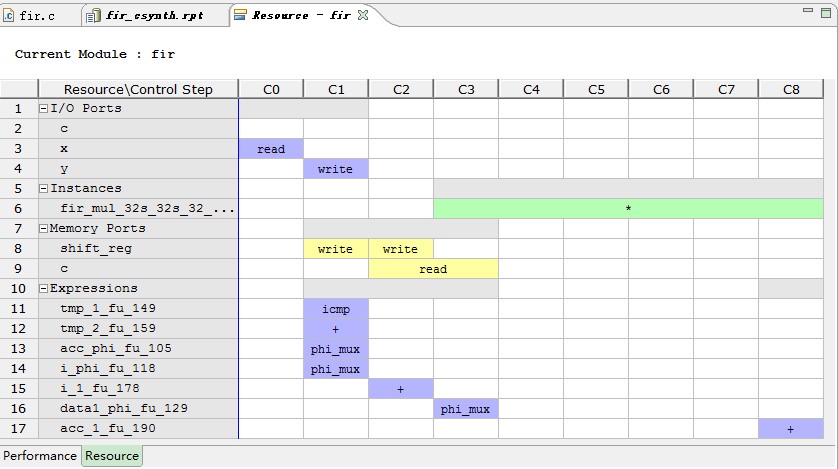
图3 资源利用率的详细视图
从图2中可以看出,源程序中for循环需要多个时钟周期才能完成,造成了我们的设计存在较大的延时,这是因为目前的综合结果是把for循环编译为一个对象,然后多次调用,这样虽然节省了硬件资源,但是因为串行执行,减小了执行速度;如果我们以设计的运行速度为指标,则可以把for循环改为并行执行的。从图3中可以看出,源程序中的数组被综合为移位然后寄存的逻辑,并且用BRAM实现的,如果把它改为用移位寄存器SRL来实现,则效率会更高。因此,我们对程序性能的优化就从这两个方面考虑。
在Vivado HLS中再新建一个solution,并点击菜单栏的Project---Close Inactive Solution Tabs,关闭其它已打开的解决方案。然后双击打开源程序,并在Directive视图中for循环上点右键,插入新的设计规则,如图4所示。
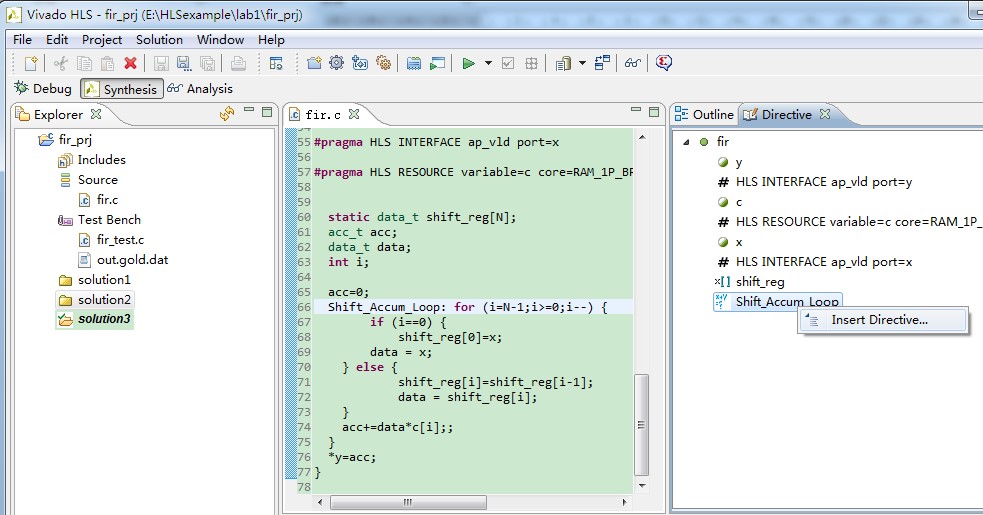
图4 为代码制定设计规则
然后为for循环指定Unroll的规则,为shift_reg指定Array_Partition的规则,如图5所示。
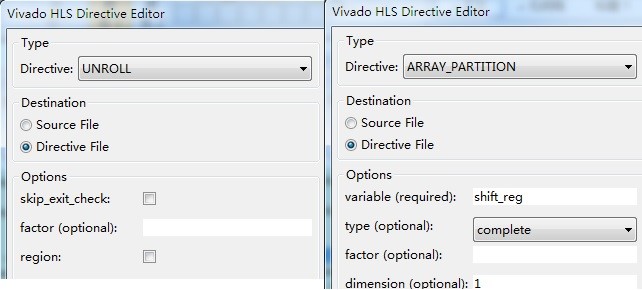
图5 程序优化使用的规则
然后再运行C代码的综合。接下来就要比较几个solution下的结果了。点击Vivado HLS工具栏Project下面的compare results,选择要对比的几个solution的报告,然后对比结果就生成了,如图6所示。
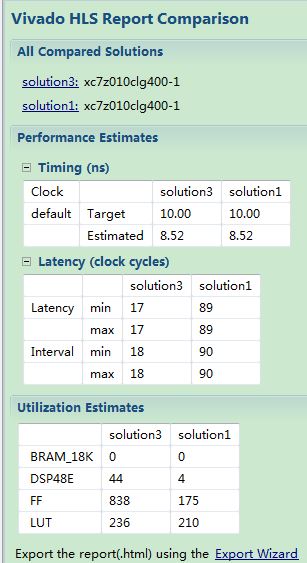
图6 优化之后的结果
由图6可见,把for循环从串行改为并行,并且把移位逻辑用SRL实现之后,程序的延迟减小到原来的1/5,而资源利用率有上升,这也是FPGA设计中“空间换时间”的典型体现。
更多的优化规则请参考ug902 HLS的用户指南,谢谢支持。

